Cans of Worms: Benchmarking finding an element in array
This starts with comparative programming. I had reason to code some Python recently, and I discovered that there was a built-in to tell if an element is in a list.
if word in list:
whatever(word)
That’s a fairly common test, and there isn’t a One True Solution for it in Perl, with TMTOWTDI and all that.
Offhand, I decided to use Benchmark to determine what the best way to do the thing. I decided to try to make a determination by creating an array of X elements, creating a smaller array of Y elements to see if those elements were in that first array, and iterating over them Z times.
It’s looking like the first Z, 400 iterations, is large enough for most of the problems, so now I’m looking at filling this:
| smaller array \ larger array | 1000 | 10000 | 10000 |
|---|---|---|---|
| 5 | ? | ? | ? |
| 50 | ? | ? | ? |
| 500 | ? | ? | ? |
The Tests
So, what is being tested? The following pseudocode explains the general method,
make an array of so many even numbers
make an comparison array of so many numbers
for each value in the comparison array
check if that value is in the array
store that result in a hash table
First
Here, I’m using first from the fan-favorite module, List::Util. It’s funny; for all the talking up I do for min and max and sum0, there’s a whole lot I just don’t use.
Note: I use no warnings in this because Perl throws a warning if first doesn’t find the thing and returns undef.
use List::Util qw{ first };
my @array = map { $_ * 2 } 0 .. ( 10 * $count );
my @comp = 1 .. $count;
my %is_in_list;
for my $i (@comp) {
no warnings;
my $first = first { $_ == $i } @array;
$is_in_list{$i} =
defined $first ? 'true' : 'false';
}
Looking further, I’m thinking that any might be a better named choice, but benchmarking them against each other proved that they’re equivalent for time.
Grep
grep is a functional subroutine I used well before I had any real understanding of what functional programming is, and here, I’m using it to tell
my @array = map { $_ * 2 } 0 .. ( 10 * $count );
my @comp = 1 .. $count;
my %is_in_list;
for my $i (@comp) {
$is_in_list{$i} =
( grep { $i == $_ } @array )
? 'true' : 'false';
}
Hash
Hash has been my preferred solution for a long while. Here I check everything once and store it in a hash, so that every subsequent test is instantaneous.
my @array = map { $_ * 2 } 0 .. ( 10 * $count );
my @comp = 1 .. $count;
my %array = map { $_ => 1 } @array;
my %is_in_list;
for my $i (@comp) {
$is_in_list{$i} =
defined $array[$i] ? 'true' : 'false';
}
The Results
Checking a 1,000-element list (1,000-element) using wallclock seconds
| checking n values | First | Grep | Hash |
|---|---|---|---|
| 5 | 1 | 2 | 5 |
| 50 | 6 | 11 | 5 |
| 500 | 46 | 97 | 5 |
Benchmark warned that these few elements might be unrepresentative, so let’s look at the next one.
Checking a 10,000-element list (10,000-element array) using wallclock seconds
| checking n values | First | Grep | Hash |
|---|---|---|---|
| 5 | 13 | 19 | 103 |
| 50 | 150 | 257 | 80 |
| 500 | 1045 | 1887 | 57 |
And a chart generated in Google Sheets:
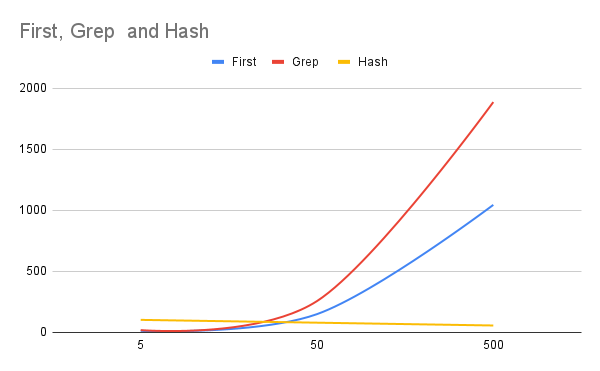
The value stored for these charts is using wallclock seconds, so, for the time to see which elements are in the array using Grep to check for 500 values took 1887 seconds, which is over a half hour., while again, while the Hash version is, within the context of the same array, essentially constant, while the other are exponential.
Conclusion
The larger the list you’re working with, the better it is to keep track of list membership if that’s a thing you need, but for smaller lists, it would be better to use Any or First or Grep.
But data size explodes, so planning ahead might be smart, making Hash a valid choice for small arrays and the best choice for bigger ones.
Which vindicates my choices, which feels good.
Code and Data
Data
========================
count: 400
array: 1000
comp: 5
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 1 wallclock secs ( 0.33 usr + 0.00 sys = 0.33 CPU) @ 1212.12/s (n=400)
(warning: too few iterations for a reliable count)
Grep: 2 wallclock secs ( 1.08 usr + 0.03 sys = 1.11 CPU) @ 360.36/s (n=400)
Hash: 5 wallclock secs ( 1.95 usr + 0.00 sys = 1.95 CPU) @ 205.13/s (n=400)
========================
count: 400
array: 1000
comp: 50
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 6 wallclock secs ( 2.26 usr + 0.00 sys = 2.26 CPU) @ 176.99/s (n=400)
Grep: 11 wallclock secs ( 4.57 usr + 0.02 sys = 4.59 CPU) @ 87.15/s (n=400)
Hash: 5 wallclock secs ( 1.36 usr + 0.00 sys = 1.36 CPU) @ 294.12/s (n=400)
========================
count: 400
array: 1000
comp: 500
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 46 wallclock secs (17.81 usr + 0.11 sys = 17.92 CPU) @ 22.32/s (n=400)
Grep: 97 wallclock secs (43.08 usr + 0.12 sys = 43.20 CPU) @ 9.26/s (n=400)
Hash: 5 wallclock secs ( 1.70 usr + 0.05 sys = 1.75 CPU) @ 228.57/s (n=400)
========================
count: 400
array: 10000
comp: 5
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 13 wallclock secs ( 4.03 usr + 0.03 sys = 4.06 CPU) @ 98.52/s (n=400)
Grep: 19 wallclock secs ( 6.51 usr + 0.03 sys = 6.54 CPU) @ 61.16/s (n=400)
Hash: 103 wallclock secs (43.47 usr + 0.28 sys = 43.75 CPU) @ 9.14/s (n=400)
========================
count: 400
array: 10000
comp: 50
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 150 wallclock secs (55.47 usr + 0.25 sys = 55.72 CPU) @ 7.18/s (n=400)
Grep: 257 wallclock secs (105.11 usr + 0.28 sys = 105.39 CPU) @ 3.80/s (n=400)
Hash: 80 wallclock secs (30.44 usr + 0.25 sys = 30.69 CPU) @ 13.03/s (n=400)
========================
count: 400
array: 10000
comp: 500
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 1045 wallclock secs (448.34 usr + 1.36 sys = 449.70 CPU) @ 0.89/s (n=400)
Grep: 1887 wallclock secs (837.35 usr + 2.70 sys = 840.05 CPU) @ 0.48/s (n=400)
Hash: 57 wallclock secs (30.45 usr + 0.06 sys = 30.51 CPU) @ 13.11/s (n=400)
========================
count: 400
array: 100000
comp: 5
Benchmark: timing 400 iterations of First, Grep, Hash...
First: 117 wallclock secs (55.00 usr + 0.27 sys = 55.27 CPU) @ 7.24/s (n=400)
Grep: 176 wallclock secs (75.20 usr + 0.41 sys = 75.61 CPU) @ 5.29/s (n=400)
Hash: 899 wallclock secs (379.11 usr + 1.31 sys = 380.42 CPU) @ 1.05/s (n=400)
Code
#!/usr/bin/env perl
# elements_in_list.pl
use strict;
use warnings;
use experimental qw{ say signatures state fc };
use Benchmark qw{ :all };
use List::Util qw{ first };
# originally wrote this to switch between
# different iteration counts and different
# array sizes, but the sweet spot for
# learing is 400 iterations and an array of
# 10,000 elements.
for my $count (qw{ 400 }) {
for my $array (qw{ 10000 }) {
for my $comp (qw{ 5 50 500 }) {
say <<~"END";
========================
count: $count
array: $array
comp: $comp
END
timethese(
$count,
{
'First' => sub {
my @array = map { $_ * 2 } 0 .. ( 10 * $array );
my @comp = 1 .. $comp;
my %is_in_list;
for my $i (@comp) {
no warnings;
my $first = first { $_ == $i } @array;
$is_in_list{$i} =
defined $first ? 'true' : 'false';
}
},
'Grep' => sub {
my @array = map { $_ * 2 } 0 .. ( 10 * $array );
my @comp = 1 .. $comp;
my %is_in_list;
for my $i (@comp) {
$is_in_list{$i} =
( grep { $i == $_ } @array )
? 'true'
: 'false';
}
},
'Hash' => sub {
my @array = map { $_ * 2 } 0 .. ( 10 * $array );
my @comp = 1 .. $comp;
my %array = map { $_ => 1 } @array;
my %is_in_list;
for my $i (@comp) {
$is_in_list{$i} =
defined $array[$i] ? 'true' : 'false';
}
},
}
);
}
}
}
exit;